
Por Peter Kraus
Grades estatísticas são convenções locais de cada nação: é uma boa prática garantir a interoperabilidade de dados espaciais do país, caberia ao governo exigir que dados por exemplo do Censo, do Meio Ambiente e da Fazenda sejam publicados neste tipo de grade padronizada.
Matematicamente a grade estatística pode ser imaginada como um mosaico de ladrilhos quase idênticos (igual área) recobrindo o território nacional. Podem ser triângulos, quadradados ou hexágonos.
A maioria das convenções desse tipo abrange mais de uma escala, ou seja, cada ladrilho do mosaico pode ser subdividido ele mesmo numa pequena sub-grade, resultando num conjunto hierárquico de grades com ladrilhos cada vez menores, contidos exatamente nos ladrilhos do nível anterior.
As grades nacionais tentam encaixar o mapa do país numa caixa. Imaginando uma caixa quadrada, veremos a hierarquia surgir de sucessivas partições desse quadrado original de lado h0 em quadrados menores, compondo grades mais e mais refinadas:
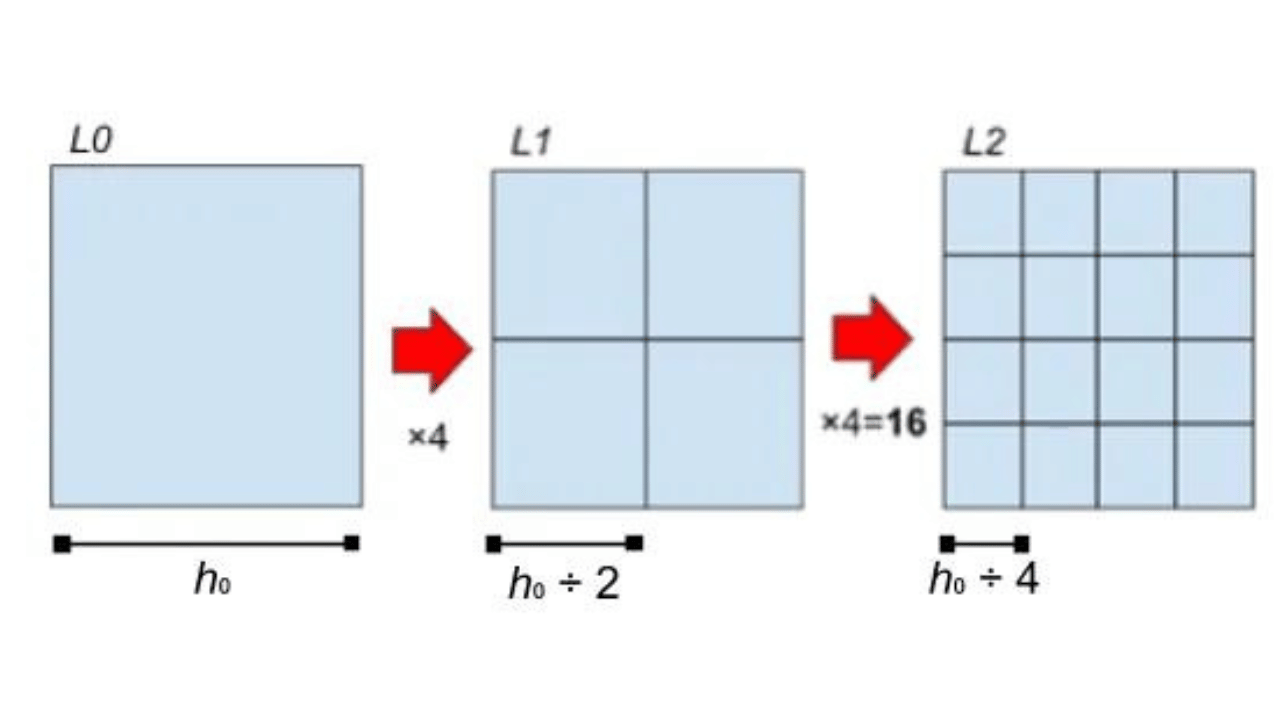
Se fosse o Brasil, necessitaria de uma caixa L0 com lado de h0 = ~5000 km.
A grade oficial brasileira, mantida pelo IBGE, usa um modelo um pouco diferente: definiu um mosaico de ladrilhos cobrindo o território brasileiro e, só depois, estabeleceu que cada um desses ladrilhos da cobertura inicial é que sofre a partição recursiva padronizada (no caso em 25 partes ao invés de).
… A Grade Estatística brasileira infelizmente é pouco conhecida e pouco usada, inclusive poucos de nós aqui do Fórum (quem já conhecia levanta a mão!).
Grade IBGE, a nossa grade
Não é só coisa dos matemáticos estatísticos… Tem até um filminho didático para usar na escola!
O IBGE mantém um repositório estável com a grade em formato shape e dados sobre densidade populacional. É tudo bem acessível:
- Pasta tipo FTP com dados para baixar;
- Documento descritivo acadêmico com todos os detalhes (ou procure documento
grade_estatistica.pdfna pasta FTP)
Cidadãos do Brasil, cientistas de dados… Por favor divulguem, usem e abusem da Nossa Grade Estatística!
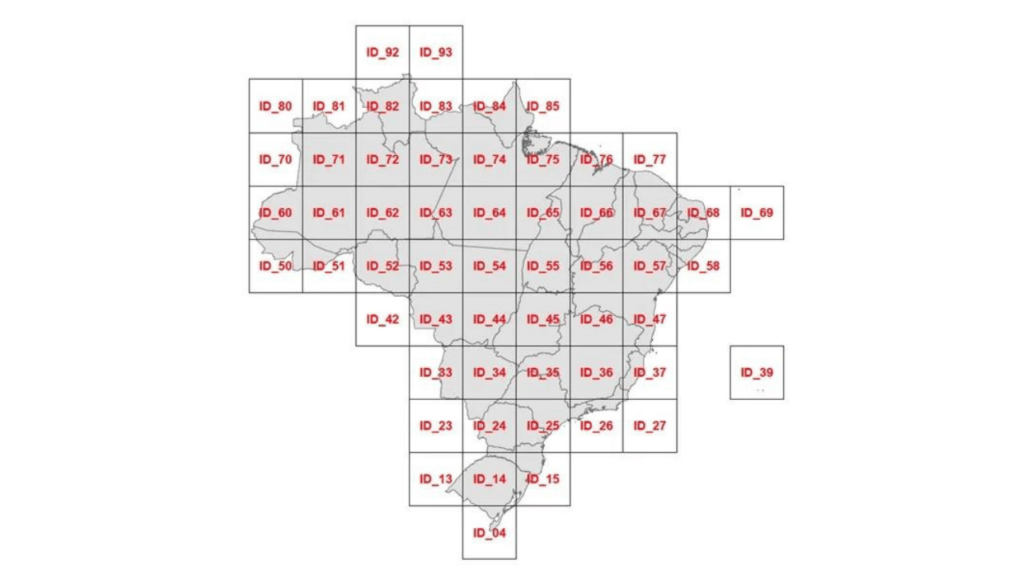
Essa é a “grade de cobertura” comentada acima. As demais grades, mais refinadas, se originam das partições recursivas, de cada quadrado em 25 quadrados menores. Cada grade portanto pode ser referenciada pelo seu nível L de particao recorrente. É um conjunto padronizado de 7 grades distintas, organizadas por tamanho de lado da célula:
- h0=500 km no nível L0 (seria nível L1 se partissemos da caixa como L0),
- h1=100 km no L1,
- h2=50 km no L2,
- h3=10 km no L3,
- h4=5 km no L4,
- h5=1 km no L5 e
- h6=200 m no L6.
Cada célula da grade de nível L<6 corresponde à união de 25 células de nível L+1.
PS: repare que o Brasil da Ilustracao tem 10 celulas de largura, portanto 10*h0=5000 km de largura, conforme estimado anteriormente.
Na ilustração acima (articulação do L0) percebemos que cada célula, também apelidada de “quadrante”, tem um identificador… Como esse indentificador é um código e pode ser utilizado como localizador (por ex. o município do Chuí fica dentro do quadrante ID_04), dizemos que a grade define um sistema de geocódigos.
Exemplo de uso:

Acima uma foto da tela da grade interativa, com dados de densidade populacional, disponível em https://mapasinterativos.ibge.gov.br/grade/default.html
A linha poligonal preta fina, envolvendo de Ibiuna até Osasco, serviu de referência para agregar a distribuição populacional, com resultados no quadro azul.
Nomes feios
E para indicar uma célula específica, falar dela, como são os “nomes de célula” (códigos) da grade do IBGE?
Todas as células foram batizadas, e os nomes cumprem seu papel de identificar unívocamente. Por exemplo a célula batizada 100KME5700N8750, da grade do nível L1, representa um quadrante com 10.000 km² de área e 100 km de lado; dentro dela, do nível L2, tem a célula 50KME5750N8750, com 50 km de lado.
Podemos dizer, em matematiquês, que a célula grande contém a pequena, 100KME5700N8750 ⊃ 50KME5750N8750. Esse tipo de relação algébrica espacial existe para todas as células da grade, nas grades dos níveis L1 em diante: toda célula tem mãe na grade de nível L-1. Outros exemplos, expressando uma hierarquia:1KME5799N8781 ⊂ 5KME5795N8780 ⊂ 10KME5790N8780 ⊂ 50KME5750N8750 ⊂ 100KME5700N8750
Por outro lado, só de bater o olho nestes exemplos já percebemos que são nomes deselegantes, grandalhões. E infelizmente, não dá para “sacar o nome da célula-mãe” só olhando para o nome da célula.
São nomes longos se comparados com o padrão Geohash, que batiza de 6gy a uma célula de 150 km de lado, e dentro dela 6gyc, com ~30km de lado (~700 km²). Ainda comparando, em termos de hierarquia, reparamos que o prefixo 6gy é o rótulo da sua célula-mãe. Algebricante 6gy ⊃ 6gyc. Outros exemplos: 6 ⊃6g ⊃6gy ⊃ 6gyc ⊃ 6gyce ⊃ 6gycex.
Resumindo os problemas com o código de célula do IBGE:
- são muito longos, difíceis de lembrar, a ponto de dificultar a comunicação;
- não são hierárquicos, não identificam os “pais da célula”; as relações algébricas de parentesco não aparecem como relações sintáticas entre prefixos de código.
O problema tem solução, podemos discutir por aqui (!).
Mais usos: porque não uma grade multifinalitária?
Independente dos rótulos de célula serem bonitos ou feios, a Grade Estatística consiste de uma parte da infraestrutura nacional de dados espaciais relevante. Ela pode ser reutilizada em diversos contextos onde há demanda por adoção de um padrão.
Reutilizar em Meio Ambiente, Economia, Saúde, Educação… Até em Logística.
O uso mais popular de um geocódigo nacional, conhecido aqui de todos, talvez seja o CEP dos Correios, que nem sequer é um dado aberto 1: passaria a ser aberto e mais eficiente.
Hoje inclusive o governo de São Paulo já namora com a Google um substituto mais moderno para o CEP, que seria o PlusCodes . É interessante esse movimento para despertarmos sobre a relevância dos cadastros de endereços postais e tecnologias de localização, para o governo e a iniciativa privada.
É momento de nos mobilizarmos um pouco por padrões abertos, soberania, estudos técnicos, licitação transparentes, etc. É também momento de oferecermos uma alternativa, buscarmos uma solução técnica que atenda a um espectro mais amplo de demandas… Que tal discutir por aqui as alternativas, e uma eventual proposta de CEP baseado na Grade Estatística?
Nome feio tem solução
A Grade Estatística já é um padrão consolidado e em uso, e será de grande importância para o Censo de 2021. Na versão vigente da Grade não se mexe mais, até pelo menos 2022… Então, para chegarmos em 2022 com uma proposta convincente, o ideal é começar revisando os modelos que deram origem ao padrão IBGE.
Origem da feiura dos nomes de célula na grade IBGE
A equipe que desenvolveu a Grade Estatística no IBGE, em ~2015, adotou um padrão de referência europeu de ~2010, o INSPIRE. Infelizmente, e sem trocadilhos, foi uma inspiração ruim quanto ao geocódigo, não melhorou nem com a revisão de 2014, que resultou no INSPIRE D2.8.I.2 v3.1.
O que parece ter acontecido rentemente é um movimento de revisão do INSPIRE D2.8.I.2, como podemos verificar neste documento de 2019, “GSGF Europe -Implementation guide for the Global Statistical Geospatial Framework in Europe”. Ao que tudo indica haverão modificações, podendo até incorporar o conceito de DGGS da OGC, definido pelo padrão “Topic 21: Discrete Global Grid Systems abstract specification” , de 2017.
Alternativas para embelezar
Como foi sugerido na apresentação do tema, o Geohash seria uma ótima alternativa em termos de “geocódigo bonito”. Mas um dos requisitos fundamentais da Grade Estatística, é que as células de grade (de um mesmo nível hierárquico L) tenham todos a mesma área. Com Geohash isso não ocorre, e haveriam distorções ao compararmos células do Pará com células do Paraná.
Na ilustração abaixo podemos notar que o Geohash 6gk sobre Curitiba é ligeiramente mais fino do que o 6z6, sobre Altamira. Medindo são 24459 km² no norte e 22022 km² no sul, a diferença de 2437 km² representa mais que 10%.
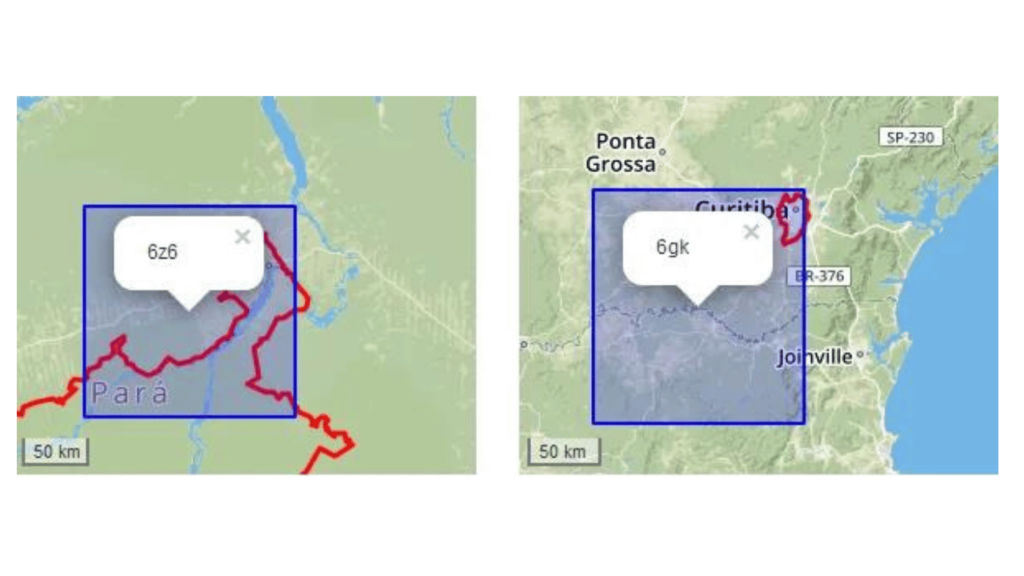
O PlusCodes da Google é baseado no OLC, que por sua vez é muito parecido com o Geohash, a ponto de padecer do mesmo problema. Não existem muitos outros padrões abertos “decentes”, o mais promissor o sistema S2 Geometry, que garante células de área quase constante, mas não tanto quanto o IBGE vigente, além de perder totalmente a compatibilidade com ele.
Se for para radicalizar, perder 100% da compatibilidade com a grade brasileira viente, o ideal é buscar algo que satisfaça os requisitos de DGGS. Pode-se usar o projeto DGGRID ou, o já bem avançado sistema H3geo da Uber.
Células de mesma área
A grade IBGE é perfeita para aplicações estatísticas pois todas as células da grade possuem mesma área. O Geohash, como demonstrado, não satisfaz os critérios de equivalência de área exigidos por aplicações estatísticas.
Bom lembrar que, quando visualizamos lotes, quadras e ruas nos mapinhas da Web (OpenStreetMap, BING, Google-Maps, etc.) a visualização privilegia a preservação dos ângulos desses objetos, e não muito as suas áreas. Na visualização Web as latitudes e longitudes dos dados são transformadas através da projeção cartográfica Web Mercator. A Grade IBGE foi obtida com Projeção Albers, a mágica que garante a equivalência de área.

Por isso na visualização da Grade IBGE também podem haver pequenas distorções, ou seja, os quadradinhos dela podem não parecer perfeitamente quadrados na visualização Web.
Bom, voltando… E se modificarmos o algoritmo do Geohash para usar ao invés da latitude/longitude direto, usar as coordenadas obtidas da projeção Albers?
Certo, a solução do problema é simples assim!
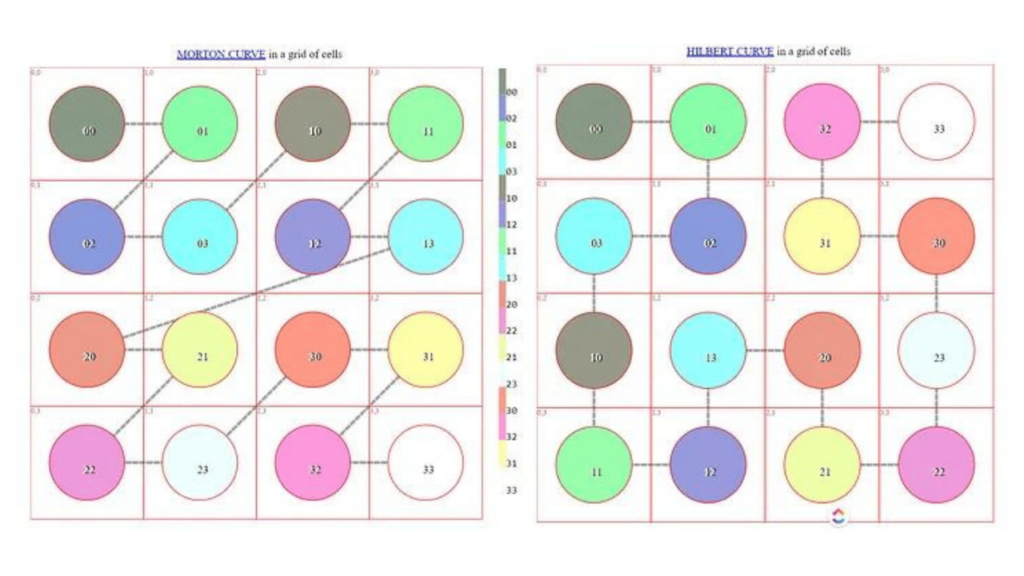
Felizmente é possível, basta adaptar o algoritmo principal Geohash, que é a indexação das células pela curva de Morton, submeter a essa indexação as coordenadas obtidas projeção Albers.
Em termos técnicos, num contexto SIG (Sistemas de Informação Geográfica), a projeção Albers brasileira 1 fica definida pela sua “Proj.4 string”+proj=aea +lat_0=-12 +lon_0=-54 +lat_1=-2 +lat_2=-22 +x_0=5000000 +y_0=10000000 +ellps=GRS80 +units=m +no_defs
Proposta da nova Grade Estatística
Na Grade vigente, limitada a 7 níveis hierárquicos, cada célula de nível L é refinada em 25 células do nível L+1. Com a adoção do algoritmo Geohash adaptado, cada célula de nível L será refinada em 4 células do nível L+1. Haverão muito mais níveis, mas, como não existem muitos múltiplos comuns para 4 e 25, poucos níveis serão compatíveis em tamanho de célula. O primeira decisão é sobre qual será o nível compatível.
Nesta proposta de nova grade, agora que mantivemos a compatibilidade com a projeção Albers, a sugestão que é que se adote um nível onde a célula tenha 1 km² , alinhando com o nível L6 da grade vigente.
Conforme a apresentação do tema no inicio da página, se fosse o Brasil, necessitaria de uma caixa L0 com lado de h0 ≥ ~5000 km. Utilizando o menor valor de h0 possível para se encaixar perfeitamente as grades nova e vigente de 1 km, a nova grade teria os seguintes níveis:
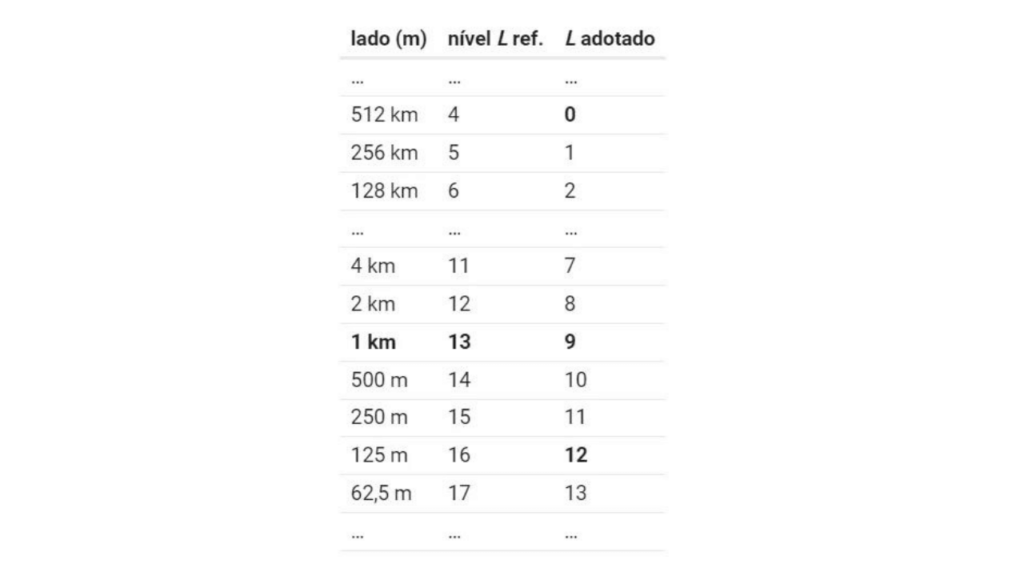
Reparem que o 512 é próximo de 500… As células de 512 km de lado, da nova grade, podem ser relacionadas ao padrão IBGE vigente de 500 km (diferem em apenas 2%). Aproveitando esse quase-alinhamento podemos manter uma certa compatibilidade com a convenção do IBGE de iniciar por uma cobertura de 56 células (da “ID_04” mais ao sul até a “ID_93” mais ao norte).

Então, o nível zero da hierarquia passa a ser cada uma dessas células previamente identificadas.
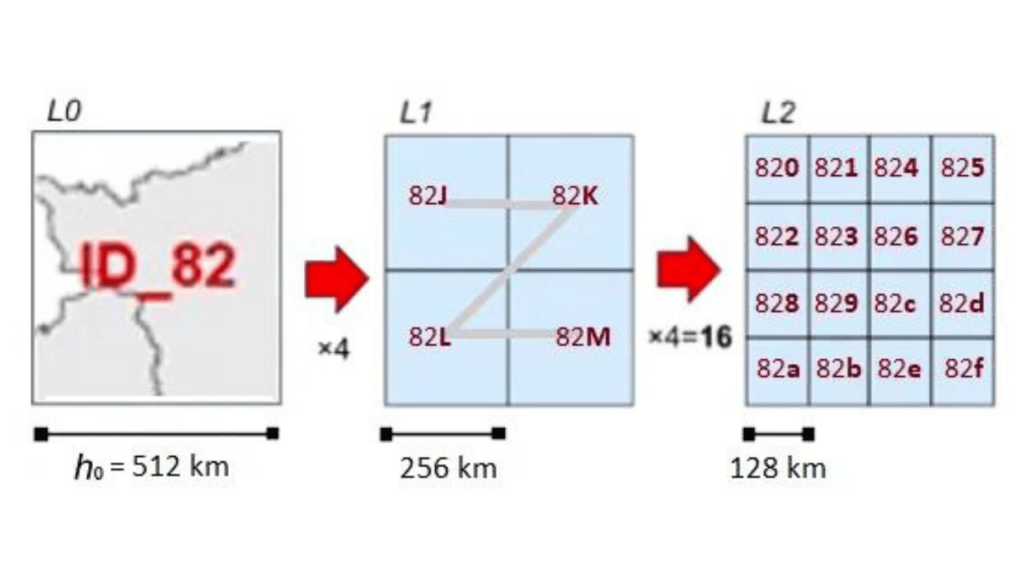
As células de cada novo nível hierárquico são indexadas conforme a Curva de Morton (também chamada “Curva Z” como se percebe no L1 ilustrado), de forma que não há limite para o número de níveis de refinamento. Para compactar a representação numérica usamos a uma variação da base 16, apelidada de base 16h, que preserva a hierarquia.
Agora as partições preservam o nome da célula-mãe. Pela ilustração percebe-se foi concatenado dígito de número ou letra para distinguir da mãe: níveis pares acrescentam dígitos da base 16 tradicional, níveis ímpares e “níveis meio” acrescentam letras da base 16h.
Na nova grade, no nível L12 com células de 125 m de lado, teríamos um geocódigo hierárquico de 9 dígitos, menor que os 15 caracteres do padrão vigente para células até maiores, de 200 m.
A nova grade, tal como Geohash, também poderia fazer uso de níveis hierárquicos intermediários, permitindo uma gradação de geocódigos ainda mais flexível, resultando num total de 24 níveis se pararmos no nível L12.
Para aplicações estatísticas e de visualização de dados, todo esse esquema de representação orientado à base 16 é razoável e oferece a flexibilidade necessária.
Em aplicações como a do CEP (localizar endereços postais), para que o código seja mais compacto (menos dígitos), adota-se a base 32. Estima-se que com 9 ou 10 dígitos teríamos uma resolução de ~5 metros, melhor portanto que o PlusCodes de 11 dígitos.
Este foi um resumo dos resultados da análise e de alguns testes práticos, realizados em 2019 por um pequeno grupo de membros da Comunidade OpenStreetMap Brasil, do qual faço parte. Estamos abertos a discussões e colaborações.
NOTA 1
Quando digo “DGGS promissor” é algo baseado em uma grade de quadriláteros. Entre os modernos e bem implementados, até onde sei, existe a apenas o tal pacote DGGRID… Nele tem as pções de “diamond cells” nas projeções ISEA4D e FULLER4D.
Aparência de um DGGS com células quadriláteras:

PS: muito se fala do S2geometry da Google, mas para ser um DGGS precisa oferecer maior garanta de equivalência de área entre as células de diferentes cantos do globo (numa grade de mesmo nível hierárquico).
NOTA 2
A minha insistência em grades quadriláteras (não triangulares ou hexagonais) se deve ao fato de que bons geocódigos só são possíveis com quadriláteros. Tentarei resumir a explicação, que não é lá muito evidente nem divulgada.
Hexágonos devem ser descartados porque é matematicamente impossível garantir a relação mãe-filha-neta no geocódigo identificador das células de uma grade hexagonal. Essa relação é fundamental nos sistemas mundanos tipo CEP, ou qualquer outro para aplicações em demarcação de terras, identificação de lotes, etc.
Triângulos são uma opção no DGGRID, mas geocódigos de nível intermediário não são possíveis com triângulos (não poderíamos usar todos os dígitos da base32 por exemplo). Além disso, em geral não são uma coisa simples e didática de usar, nem temos tradição de olhar para um mapa através de uma grade triangular para por exemplo fazer estudos estatísticos.
Nesta demo, veja a figura abaixo, tem como selecionar níveis intermediários (1.5, 2.5, etc.) para entender como geocódigos de níveis intermediários (incluindo base32) podem ser obtidos nas células quadriláteras.
Por fim tem o argumento do próprio pessoal do IBGE, de que o Brasil não tem “maturidade” (em informática e geoprocessamento) para o DGGS hexagonal, está a algumas décadas de distância de poder adotar isso como “padrão transparente e inteligível”.
AFA codes: Trazemos um Código de Endereçamento, Geodigital frente ao CEP que temos hoje

É o geocódigo ISO da cidade, BR-SP-SaoPaulo (um mnemônico padronizado e mais curto que as longas frases do PlusCodes), seguido da localização do ponto, MCGBM. Faz uso de tecnologia similar ao Geohash, com quadradinhos de igual-área, da Grade Estatística do IBGE, para ser multifinalitário.
Esse código, MCG.BM, tem 5 dígitos e representa um retângulo com lados de ~5,5 metros.
O seu similar em Goole PlusCodes, C9X8+RC, consome 6 dígitos para um quadrilátero de ~13 m de lado.
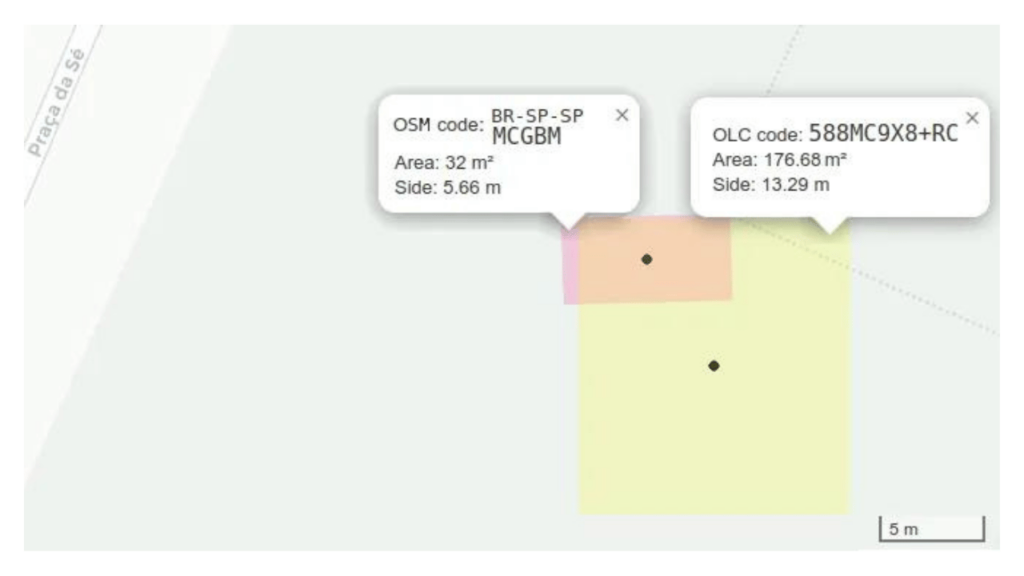
O AFA.codes portanto, com relação ao padrão OLC com encurtamento PlusCodes, é bem superior:
- mesmo com um dígito a menos oferece mais precisão (célula com 1/5 da área do OLC ilustrado);
- o prefixo mnemônico de nome de cidade faz sentido para o cidadão brasileiro e é curto,
“BR-SP-SP” é bem mais simples que “São Paulo, State of São Paulo, Brazil”; - dados e algoritmos abertos: ao contrário da caixa-preta dos nomes do Plus Codes;
- multifinalidade: por serem células de igual-área, baseadas no padrão nacional (a Grade Estatística do IBGE), o AFA.codes postal é interoperável com dezenas de outras aplicações.
O AFA.codes como tecnologia do “novo CEP” também permitiria a localização da porta de casa em comunidades densas (tipicamente favelas), com resolução de exatamente 1 m², BR-SP-SP~MCG.BM7.
Grade multifinalitária
A “multifinalidade” do Novo CEP vem de outras aplicações. Permite por exemplo expressar quadrantes do mapa de atendimento emergencial do SUS e do Corpo de Bombeiros, que precisam ser maiores, da ordem de 1 km de lado. Por ser um geocódigo hierárquico dígito a dígito, basta remover dígitos para chegar na escala desejada.
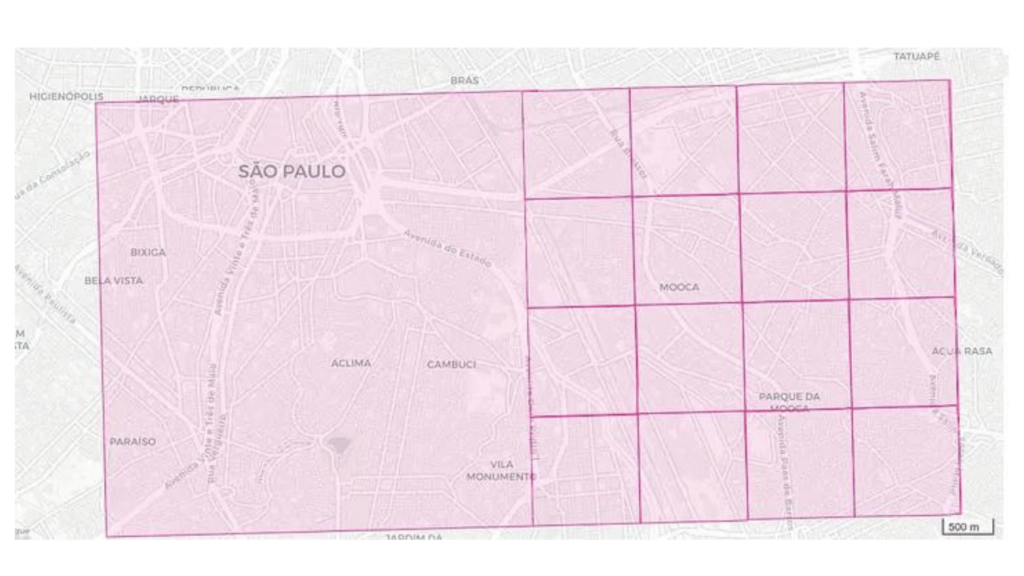
No exemplo da praça da Sé, removendo 2 dígitos da direita teremos BR-SP-SP~MC, o quadrante com 1,02 km de lado, ilustrado abaixo.

A grade multifinalitária cobre a totalidade do território, permitindo a gestão da informação relativa a cada quadrante: população, índices de ocupação, índices de cobertura vegetal, etc. podem ser comparados quadrante a quadrante por possuírem exatamente a mesma área, e podem ser referenciados em comunicados oficiais, cartórios, e outros.
É tudo um demo.
Pode experimentar outras cidades e países em https://afa.codes.
Faça o teste você mesmo pelo seu celular
… estando na sua cidade, entre no domínio afa.codes e experimente, clique no botão de “MyLocation”, que vai obter a localização GPS do seu celular, do local que você estará no momento do clique. Veja que solução fantástica! O que achou?

What We Learned in Our Webinar on Unique and Open Address Database Projects in Countries!

Delivering the BANOC Codes: A Landmark for Open Addressing in Cameroun

Overture Maps Foundation Releases General Availability of its Open Maps Datasets

Applause to IBGE for Publishing the Coordinates of 111 Million Addresses!







Hey how's it going?
Can you write your comments here?
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Hey there just wanted to give you a brief heads up and let you
know a few of the images aren’t loading properly.
I’m not sure why but I think its a linking issue.
I’ve tried it in two different internet browsers and both show the same results.
Feel free to visit my blog: dk7 เครดิต ฟรี 108
It’s going to be end of mine day, but before end I am reading this fantastic piece of writing to increase my know-how.
My webpage: online casino real money sign up bonus
Your article helped me a lot, is there any more related content? Thanks!
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?